WordPressからJekyll&S3な環境に移行した話
このブログをレンタルサーバ上のWordPressから
静的サイトジェネレータのjekyllに移行したので経緯と移行手順をまとめてみた
経緯
旧環境はレンタルサーバ上でWordPressを稼働させていた
元々更新頻度にムラっ気があって、しばらく放置してしまう時もあって
たまに記事更新をしようとするとサーバ側のPHPのバージョンが変わった影響で
WordPressのバージョン上げなきゃいけなくなってて、
バージョン上げたら今度は管理画面が真っ白になったり
記事投稿しようとすると内部エラーが出て投稿すらできず、
みたいなことが何度かあった
しかもレンサバなのでサーバ内の状態を確認しずらかったりして
管理も面倒に感じていた
WordPressの仕組みもしばらく触ってないと忘れてしまって
ちょっとした変更をしようとした時に気持ち的なハードルが高くなってしまい
どうしても作業が遅くなってしまっていた
加えて、レンサバが単純にコストかかりすぎ(1500円ぐらい毎月かかってた)
ということで
- wordpress自体がトラブった時の対応コストが高い
- レンサバなのでサーバ側の状況を把握しづらい
- サイト規模に対してレンサバのランニングコストが高い
- とはいえブログは資産なので自分で管理したい
といった部分を解決できれば個人的にはよさそうということになり、
静的サイトジェネレータ + Amazon S3 上でWebサイトホスティング
という方向でブログを移行することにした
以下、静的サイトジェネレータやS3のWebサイトホスティングの概要について
レンサバxWordPressな環境との比較も含めてまとめてみた
静的サイトジェネレータとは
そもそも静的サイトジェネレータとはなにかというと
サイトのデザインテンプレートをプログラム的に組み合わせて
記事などのコンテンツをそのテンプレート内に埋め込んで
最終的にhtmlを生成するツールということになる
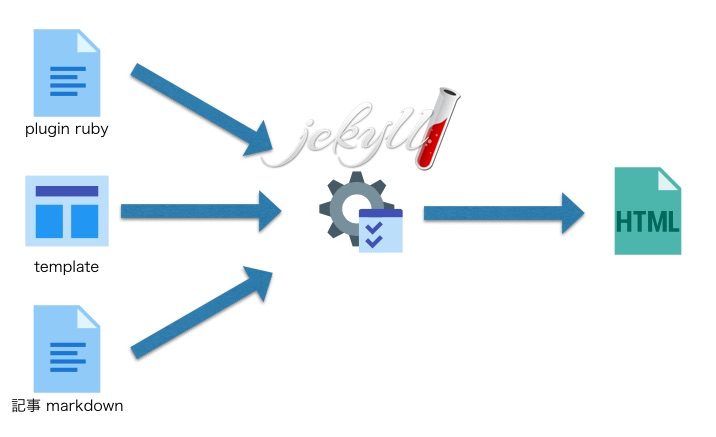
これだけ聞くとWordPressと同じじゃん、となるが
wordpressがページのリクエスト毎に動的にhtmlを生成するのに対し、
静的サイトジェネレータはhtmlを静的なファイルとして事前に全て生成する
という部分が大きな違いになる
つまり、jekyllで生成したhtmlファイルをwebサーバへデプロイし、
単純にhtmlを配信するだけのシンプルな処理になる
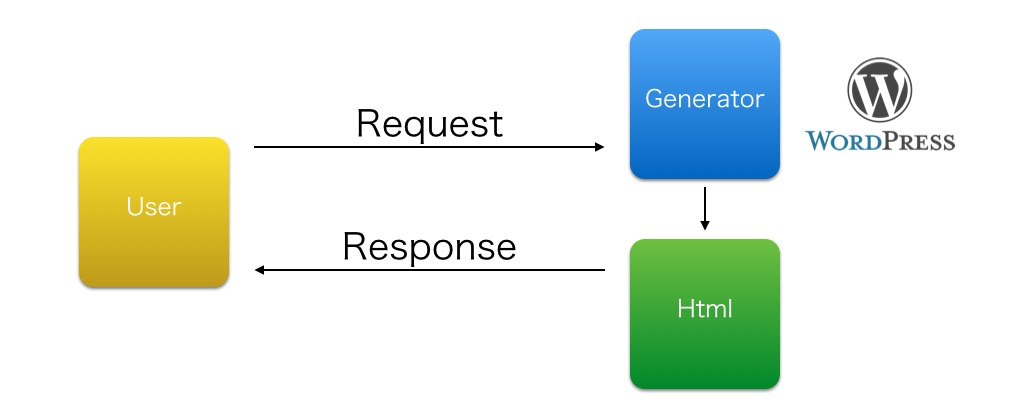
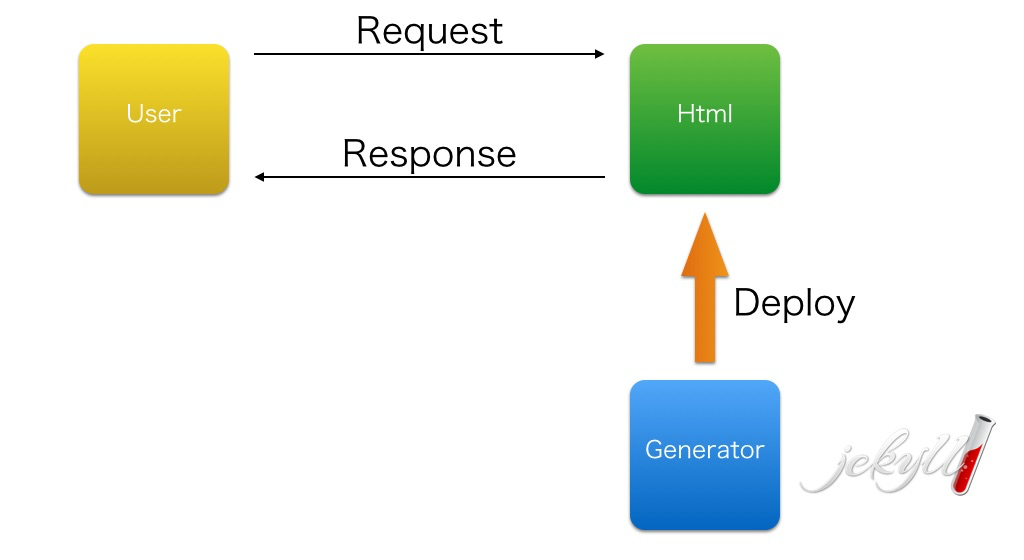
これのいいところは、単純なhtml配信となるので
- トラブルの発生確率が減る
- 万一トラブルが起きた時も仕組みがシンプルな分、解決も早い
みたいなところがある
また、WordPressはコンテンツの情報をDBに保持していて、
WordPress固有の付帯情報とともに管理されているため構造を把握しにくいが、
最近の静的サイトジェネレータの多くはMarkdown形式のテキストに
記事コンテンツを分離して管理する仕組みになっているため、
そもそもmysql自体が不要だし編集自体も直感的に、
気楽に出来るというメリットも大きい
このブログ自体、現状は大した記事量ではないし
php+mysqlなWordPressで動的に管理するのはオーバースペックかつ
管理面でのデメリットしか感じなくなったので、
記事をmarkdownなファイルで綺麗に分離できて、
サーバ負荷も低いjekyllは自分の環境にはピッタリだった
ちなみに、静的サイトジェネレータはJekyll以外にも
- Python製の Pelican
- Node.js製のHexo
等、他にもかなり沢山あるが単純に自分がrubyに慣れていたのでJekyllを選択した
https://staticsitegenerators.net
Amazon S3で低コストWebサイト運用
今回のもう一つの変更点はサーバをレンサバから
S3上でのWebサイトホスティングの形式に変更したところ
S3は一般的にはクラウドストレージサービスとして認識されているが
Webサイトのホスティング機能も提供しているので
htmlファイルをアップロードしてWebサイトホスティングを有効にすれば
そのままWebサーバとして機能させることが出来る
コスト面も、従量課金制でストレージ使用量やIOに比例してくるため、
アクセスの少ないサイトなら1ヶ月数十円ということもあり得る
大雑把にコスト計算すると大体以下のようになる
まず、ブログの1ページの内訳を大体こんな感じと仮定する
htmlファイル x 1
cssファイル x 1
jsファイル x 1
imageファイル x 7
1ページ表示時の総request数 10リクエスト
1ページ総容量200kb
S3の料金は大きく分けて3つのセクションに分かれている
- Storage
- 一月の間にS3に保管されるデータ量
- Requests
- Get、Put/Copy/Post/List等のリクエスト回数
- Data Transfer
- リージョンを跨いだデータ送信量
- 外部ネットワークへのデータ送信量
- 外部ネットワークからのデータ受信量
仮に月間平均10万PVだったとして
Storage
100page * 200kb = 20MB
最初の1TB/月 : $0.03/GB
=> 約$0.01
Requests
1page 10requests
10 * 100000 = 1000000
GETリクエスト $0.0037 / 10000requests
1000000 / 10000 * $0.0037
=> $0.37
Data Transfer
S3からのデータ転送量(アウト)
200kb * 100000requests / 1024.0 / 1024.0
=> 約19GB
最初の1GB/月 $0
10TBまで/月 $0.14
18 * 0.14
=> $2.52
total
0.03 + 0.37 + 2.52
=> $2.92
2.92 * 120 = 350 円
ここに、Route53の料金を$0.5程度考慮
350 + 60 = 400円
ということで、10万PVのサイトを400円程度で運用できることになる
レンサバが1ヶ月1500円程度掛かっていたので大幅にコストカットできた
しかも、アクセス増加によるサーバ負荷なども実質的に心配する必要もなく、
レスポンスを改善するならCloudFrontをすぐさま導入することも可能だし、
動的な処理が必要になればlamdaやapi Gatewayなんかを
活用できたりと拡張性も高い
まとめ
こんな感じで、コストカットとブログ環境のシンプル化がいい感じにできたと思う
実際の移行手順とかは長くなったので次回に
macでvimのヤンクとクリップボードを連携する
標準で入っているvimだと
vim --version | grep clipboard
をすると[-clipboard]となっていて、クリップボード連携が無効になっている
これをbrew経由で新しいvimに置き換えてクリップボード連携を有効にしてみる
新しいvimをbrew経由でインストール
brew install vim
brew経由で入れたvimでclipboard連携の状態を確認
/usr/local/Cellar/vim/7.4.889/bin/vim --version | grep clipboard
+clipboardが表示されていることを確認
既存のvimをリネームして、新しいvimへのリンクを作成
sudo mv /usr/bin/vim /usr/bin/old_vim
sudo ln -s /usr/local/Cellar/vim/7.4.889/bin/vim /usr/bin/vim
vimを起動させるとこんなエラーが出た pathが見つからないらしい
Can't open file /usr/local/share/vim/syntax/syntax.vim
とりあえず以下を追加してsyntaxが正常に動くようになったことを確認
export VIMRUNTIME=/usr/local/Cellar/vim/7.4.889/share/vim/vim74
あとは.vimrcにクリッポボード連携有効化の設定を入れるだけ
set clipboard+=unnamed
これで、vim上でヤンクした結果をクリップボードにも連携されるようになるので vim以外へペースト可能になる
clang-formatをビルド時に自動実行する
iOS開発する時のコード整形ツールとしてclang-formatを使用している。
最初はXcodeのプラグインとしてGUI上から手動実行していたが
XCodeのバージョンをあげると動かなくなったりとかで辛かったので
途中からターミナルで手動実行に切り替えた。
最終的にはビルドの時にpre-actionsでやれば整形漏れもなくなって
いいと思って、今の形に落ち着いたので導入方法メモ。
-
clang-formatをbrewからインストール
brew tap tcr/tcr brew install clang-format -
clang-format実行方法
clang-format -i -style=Google hogehoge.m -
edit schemeでpre-actionsにRunScriptを作成
schemeのRunのPre-actionsを選択、新規RunScriptを作成する
SRCROOTを使用するので「Provide build settings from」から整形対象のtargetを選択する -
RunScriptにclang-formatのコマンドを記述する
find ${SRCROOT} -name *.[h,m] | xargs clang-format -i -style=Google
これで対象のtargetをRunすると、自動でビルド前にコード整形がされるようになる
UIWebViewの初期化は結構遅いという話
当然といえば当然だけど、
初期化だけで思った以上に
時間かかっていたので記事にしてみた
こんなコードで、UIView、UIImageView、UIWebViewの三種類を
10回initした時の各処理の平均時間を出力
double starttime, endtime, totaltime;
NSArray *classArray = @[[UIView class], [UIImageView class], [UIWebView class]];
for (id obj in classArray) {
NSMutableArray *totalTimes = [NSMutableArray array];
int loopCnt = 10;
for (int i=0; i<loopCnt; i++) {
starttime= (UInt64)floor((CFAbsoluteTimeGetCurrent() + kCFAbsoluteTimeIntervalSince1970) * 1000.0);
id object = [[NSClassFromString(NSStringFromClass([obj class])) alloc] init];
endtime= (UInt64)floor((CFAbsoluteTimeGetCurrent() + kCFAbsoluteTimeIntervalSince1970) * 1000.0);
totaltime = endtime - starttime;
[totalTimes addObject:[NSNumber numberWithDouble:totaltime]];
object = nil;
}
NSLog(@"%@ avg = %@", [obj class],[totalTimes valueForKeyPath:@"@avg.self"]);
}
こんな結果になった
UIView avg = 0
UIImageView avg = 0
UIWebView avg = 212.6
UIViewとかUIImageViewの初期化は、
無視できるレベルの処理時間(1msecとか)だけど、
UIWebViewは200msec以上かかってた
あんまり意識した事なかったけど、
速度にシビアな状況だと結構気になるレベル
だということが分かった
ちなみに、環境は
MacBook Pro
CPU : Core i7 2.6GHz
MEM : 16GB
で、iphoneシミュレータ(iphone6)での結果です
追記
実機(iphone5s)でやったら全然早かった
平均30msecぐらい
これぐらいなら、よほどじゃない限り目を潰れるか
UIView avg = 0
UIImageView avg = 0.1
UIWebView avg = 31.2
レーベンシュタイン距離のアルゴリズムを理解する
二つの文字列の類似度を測れるので
メールアドレスの入力チェック等でも使われてるレーベンシュタイン距離。
rubyではgemもあるし、サンプルコードもweb上に色々あるけど
触る機会があったので、せっかくだしアルゴリズムを理解した上で
自分で焼き直してみた。
考え方
レーベンシュタイン距離は、
文字列の類似度を「二つの文字列が最短で何回の編集で同じになるか」
で表したもの。
編集とは[挿入、削除、(置換)]を指す。
一度の編集では1つの文字しか編集できない。
アルゴリズム
wikipediaのアルゴリズム説明にはこう書いてある。
レーベンシュタイン距離を計算するためには、
一般的に動的計画法によるアルゴリズムが用いられている。
長さ n と長さ m の文字列間の距離を求めるには
(n + 1)×(m + 1) の二次元行列が使われ、
計算時間はO(mn)と非常に効率がよい。
このアルゴリズムの要諦は、
1文字削った文字列の末尾にどのような文字を追加すれば一致するか見ることで、
1文字削った文字列との距離から1文字加えた文字列との距離を求めることができる
長さ 0 の文字列と長さ x の文字列の距離は x である
の2点から帰納的に求めることができるという点である。
動的計画法とか用語が分からないと戸惑ってしまうけど、図にしてみると割と簡単。
文字列A = abc
文字列B = ad
上記2つの文字列のレーベンシュタイン距離を求めてみる。
まず、2つの文字列を縦軸と横軸に一文字ずつ並べた表を作る。
| - a b c
-----------------
- |
a |
d |
各軸の最初のハイフンは空文字の意味。
後の説明のために、縦軸横軸それぞれに追加してある。
ここに、Bの文字列(Y軸)をAの文字列(X軸)にするための編集距離を追加する。
文字同士を比較して、編集が必要(追加/削除)な場合は1を加算、
一致している場合は加算しない。
一致している場合は右斜め下、追加が必要な場合は右、削除が必要な場合は下に、
という風に進んで行く。
| - a b c
-----------------
- | 0
a | 0 1 2
d | 3
もしくは
| - a b c
-----------------
- | 0
a | 0
d | 1 2 3
空文字、aは一致しているので0、2文字目以降は不一致なので
dを削除、bとcを追加(又は逆の順序で)しているので
それぞれ一つ前の値に1を加算して進み、
最終的に右下の位置までいくと一致することになる。
つまり、この図の右下にたどり着く為におこなった
編集の回数(斜め以外の移動回数)が編集距離(レーベンシュタイン距離)となる。
これを最も単純に求める方法は、
左上のセルから順に、全てのセルの値をインクリメントしてセットしていけばよい。
まずは左上セルは開始位置なので0をセット、
そのまま1行目の右方向セルに1ずつ加算した値をセットする。
これは、Y軸の空文字とa/ab/abcとの編集距離をそれぞれ登録しているという事になる。
上記のwikipediaのアルゴリズムの説明にあった
長さ 0 の文字列と長さ x の文字列の距離は x である
の部分になる。
| - a b c
-----------------
- | 0 1 2 3
次に、同様の考え方で1列目の2行目以降のセルに1ずつ加算した値をセットする。
これは、X軸の空文字とa/ab/abcとの編集距離をそれぞれ登録しているという事になる。
| - a b c
-----------------
- | 0 1 2 3
a | 1
d | 2
ここからは各行毎に左端から右端に向かって一つずつセルに値をセットして行く。
(1,1)のセルに設定する値を考える。
比較文字はX、Y共に[a]で一致しているので編集距離は加算されない。
つまり、左斜め上(0,0)のセル値と同じ値、0をセットすればよい。
| - a b c
-----------------
- | 0 1 2 3
a | 1 0
d | 2
次に右に一つ進んで(2,1)のセル値を設定する。
Xが[b]、Yが[a]なので編集が発生する。
この時、人間ならここまでの最短ルートを記憶しているので
左の0に加算をすると言う判断がすぐに出来るが、
プログラム的にはルートの記憶は考慮していないので一つ前の値となる
(0,1)と(1,0)の値を比較して、小さい方
(今回の場合は左隣の0)を選択して、そこに1を加算する。
| - a b c
-----------------
- | 0 1 2 3
a | 1 0 1
d | 2
このロジックで全て数値を埋めて行くと、
# 完成図
| - a b c
-----------------
- | 0 1 2 3
a | 1 0 1 2
d | 2 1 2 3
上記のマトリクスが完成し、右下の値が最短の編集距離となる。
という訳で、この考え方に基づいて書いたレーベンシュタイン距離を求める、
よくあるコードが以下のような形になる。(コードはruby)
# coding: utf-8
def levenshtein_distance(a ,b)
# 二つとも長さゼロの場合は差異無しとして扱う
return 0 if a.length == 0 && b.length == 0
# 片方が長さゼロの場合はもう一方の長さを返却
return b.length if a.length == 0
return a.length if b.length == 0
# 値をセットする為の2次元配列を生成
matrix = Array.new
0.upto(a.length){ matrix << Array.new}
0.upto(a.length){ |i| matrix[i][0] = i}
0.upto(b.length){ |j| matrix[0][j] = j}
# 各文字を比較して、編集距離を各セルに設定する
1.upto(a.length) do |i|
1.upto(b.length) do |j|
m = matrix[i-1][j] + 1
n = matrix[i][j-1] + 1
if a[i-1] == b[j-1]
l = matrix[i-1][j-1]
matrix[i][j] = l
else
matrix[i][j] = [m, n].min
end
end
end
# 右下のセルの値が最短編集距離
return matrix[a.length][b.length]
end
str1 = 'select'
str2 = 'inspect'
puts levenshtein_distance(str1, str2)
ちなみに、編集の定義に置換も考慮する場合は上記のコード中の
セルに値をセットしている処理部分を以下のようにすれば良い
# 各文字を比較して、編集距離を各セルに設定する
1.upto(a.length) do |i|
1.upto(b.length) do |j|
# 置換の加算値を1とする場合(編集の定義=追加/削除/置換)
x = (a[i-1] == b[j-1]) ? 0 : 1
m = matrix[i-1][j] + 1
n = matrix[i][j-1] + 1
l = matrix[i-1][j-1] + x
matrix[i][j] = [m, n, l].min
end
end